決策樹圖形無法出現
分別在pydotplus及graphviz package出現問題
無法安裝pydotplus套件
直接使用conda或pip在Python3環境下都捉不到此套件,查了下stackoverflow,可以透過conda-forge進行安裝conda install -c conda-forge pydotplusconda install -c conda-forge graphviz
- conda-forge:A community led collection of recipes, build infrastructure and distributions for the conda package manager.
- 关于conda和anaconda不可不知的误解和事实——conda必知必会
Graphviz’s executable not found
- 分別用conda及pip安裝graphviz,兩者版本不同,一個是2.38,一個為0.7,不清楚差異。
- 但兩者分別安裝後仍舊無法使用
- stackoverflow裡有人提到安裝順序的問題,應該graphviz先,再pydotplus,但試過後無用
- 最後依stackoverflow提到從graphviz官網下載msi檔案安裝,並且將graphviz/bin的路徑設定進去電腦環境的PATH中,在原眾多路徑的最後加;及graphviz/bin的絕對路徑
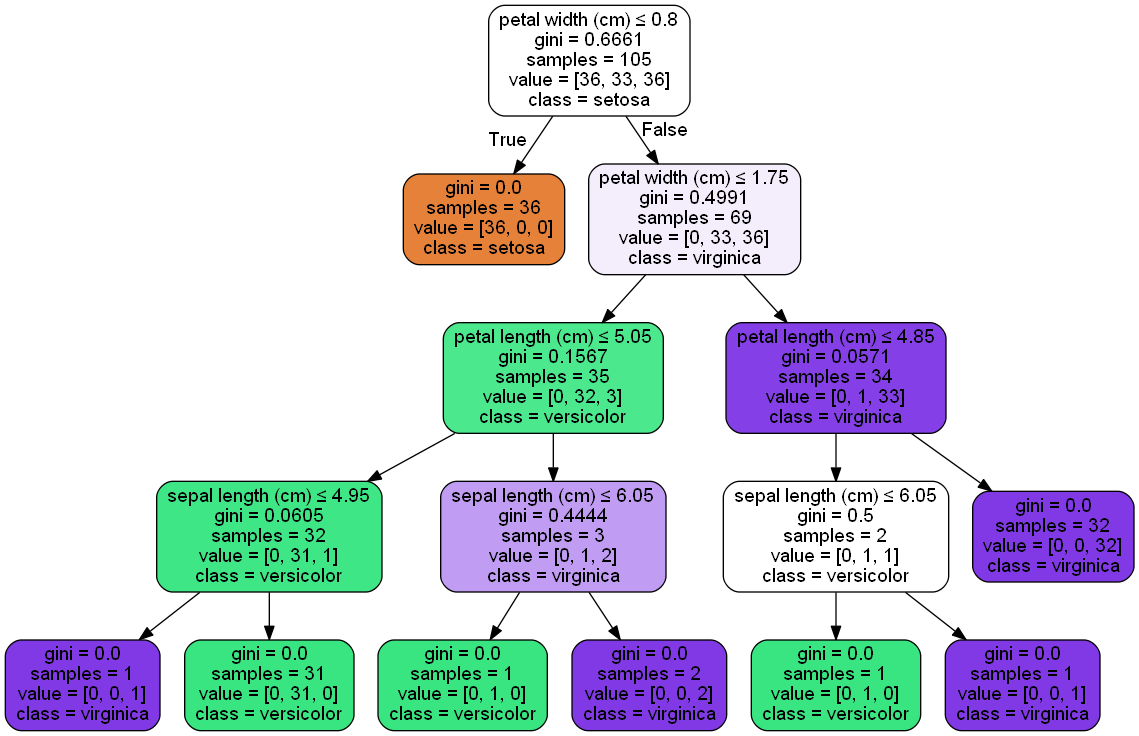
- 重新啓動python IDE即可正常產出決策樹圖形
決策樹的資料分為
- 訓練資料及測試資料各有獨立資料庫檔案
- Cross-validation,交叉驗證,即又建模又測試,主要用於資料量少時使用,因為做比較多次,資料計算較平均,但計算成本較高
如分10 folder,即代表分10大類,每次挑1個測試,另9個當變數(leave one out ),一直交換當測試 - Percentage split,多少比例用於建模,剩餘比例用於測試,主要用於資料量多時
|
|
K-folder, Cross-validation, LeaveOneOut
|
|